
Almond Jupyter API
The Almond Jupyter API can be accessed via an instance of almond.api.JupyterApi. Such an instance is created by almond upon start-up. This instance accessible via the kernel variable and in the implicit scope via e.g. implicitly[almond.api.JupyterApi].
A number of higher level helpers rely on it, and provide a more convenient API to display objects.
High level API
Display
A number of classes under almond.display provide an API similar to the IPython display module.
Examples:
// These can be used to display things straightaway
Html("<b>Bold</b>")
// A handle can also be retained, to later update or clear things
val handle = Markdown("""
# title
## section
text
""")
// can be updated in later cells
// (this updates the previous display)
handle.withContent("""
# updated title
## new section
_content_
""").update()
// can be later cleared
handle.clear()
Input
// Request input from user
val result = Input().request()
val result = Input().withPrompt(">>> ").request()
// Request input via password field
val result = Input().withPassword().request()
JupyterAPI
almond.api.JupyterApi allows to
- request input (password input in particular),
- exchange comm messages with the front-end.
- display data (HTML, text, images, …) in the front-end while a cell is running,
- update a previous display in the background (while the initial cell is running or not),
Note that most of its capabilities have more convenient alternatives, see High level API.
Request input
Call stdin on JupyterAPI to request user input, e.g.
kernel.stdin() // clear text input
kernel.stdin(prompt = ">> ", password = true) // password input, with custom prompt
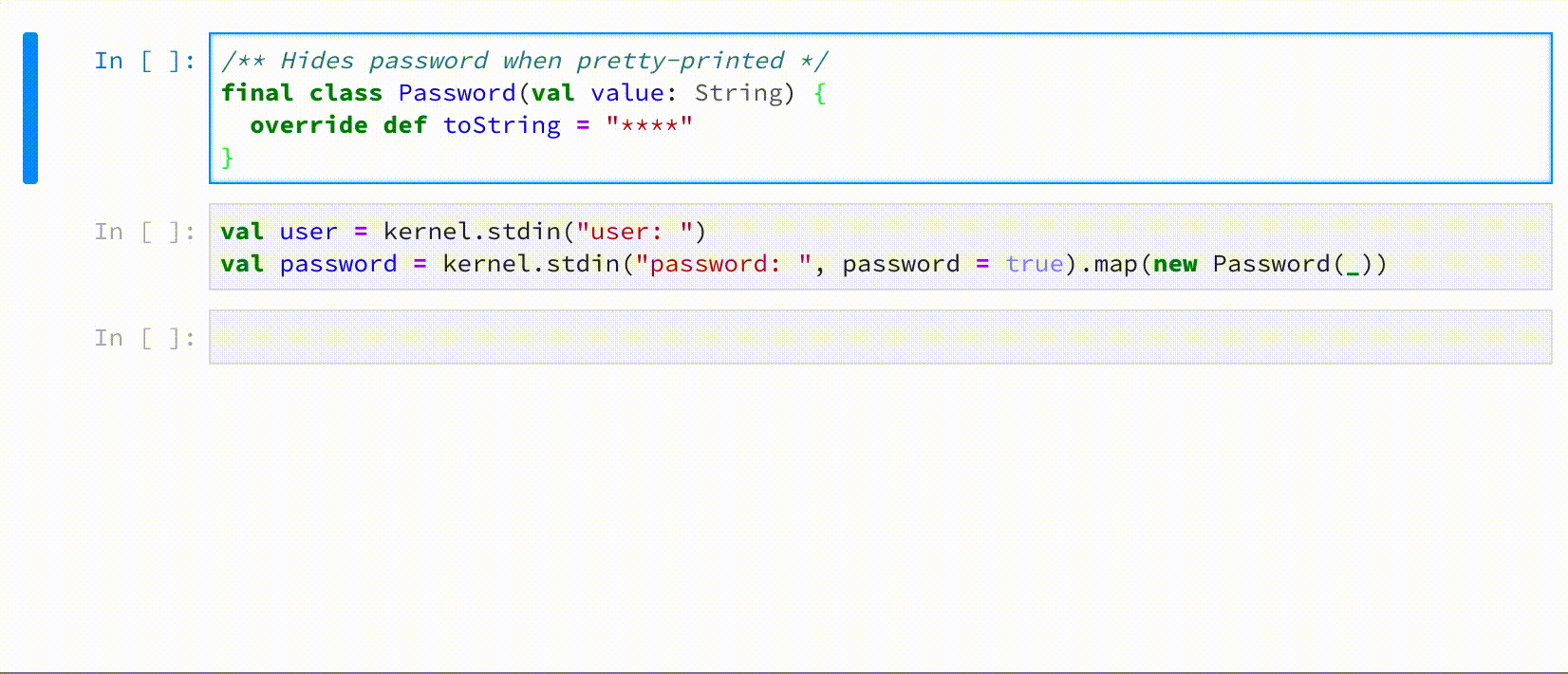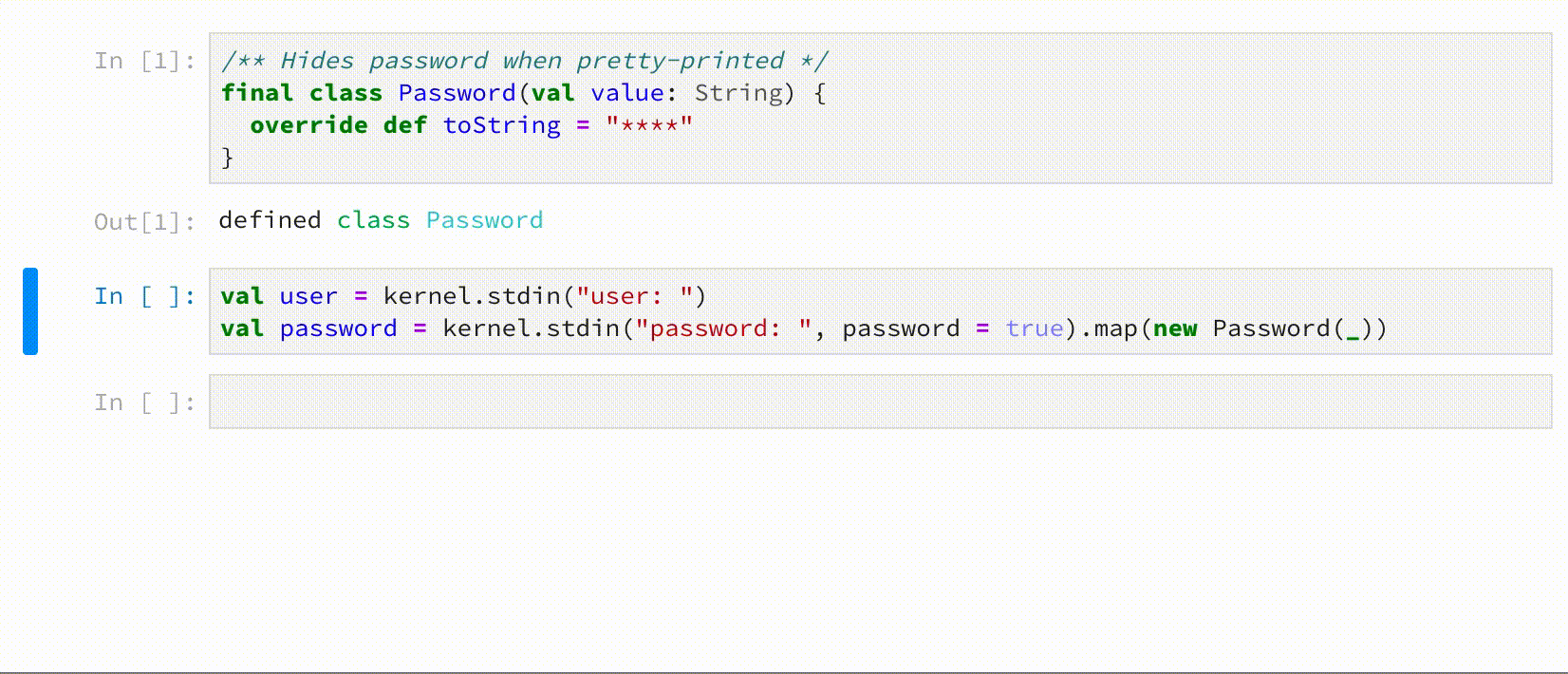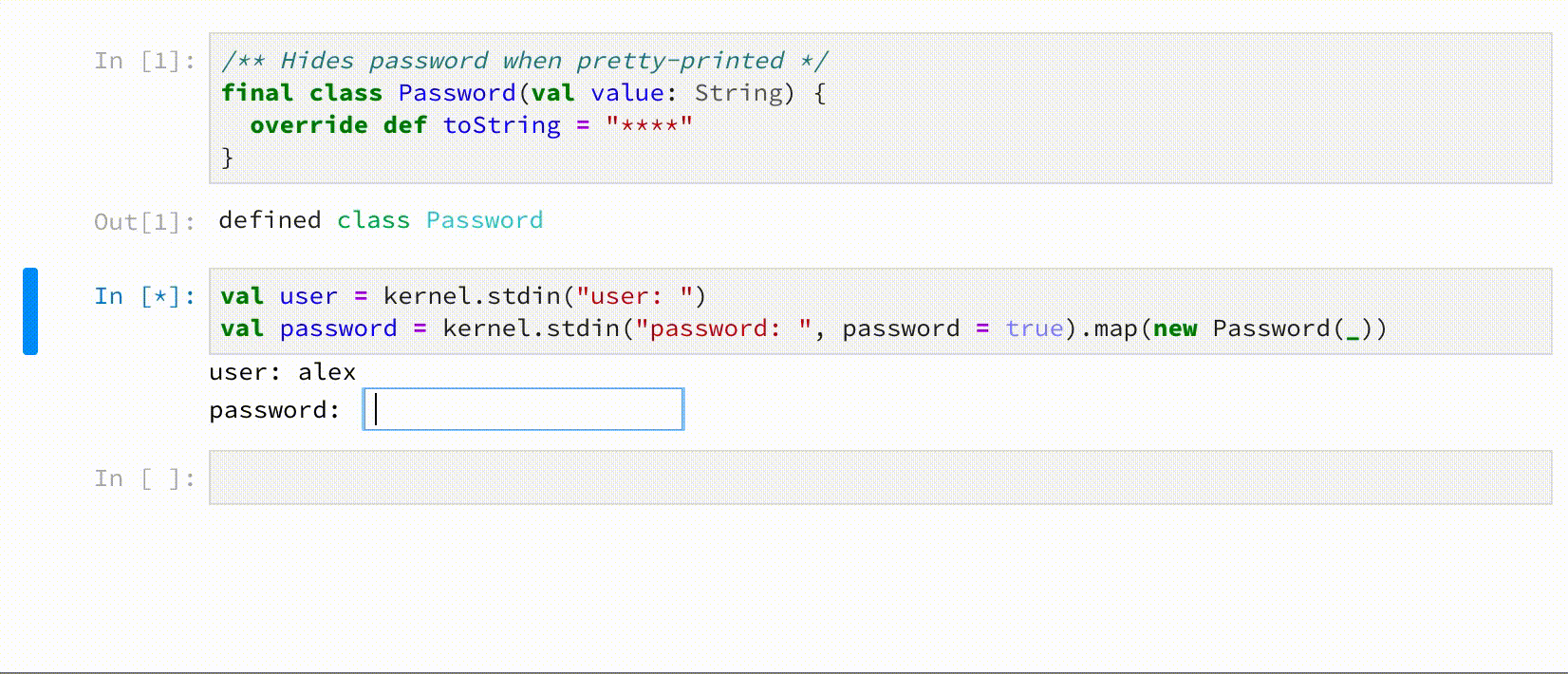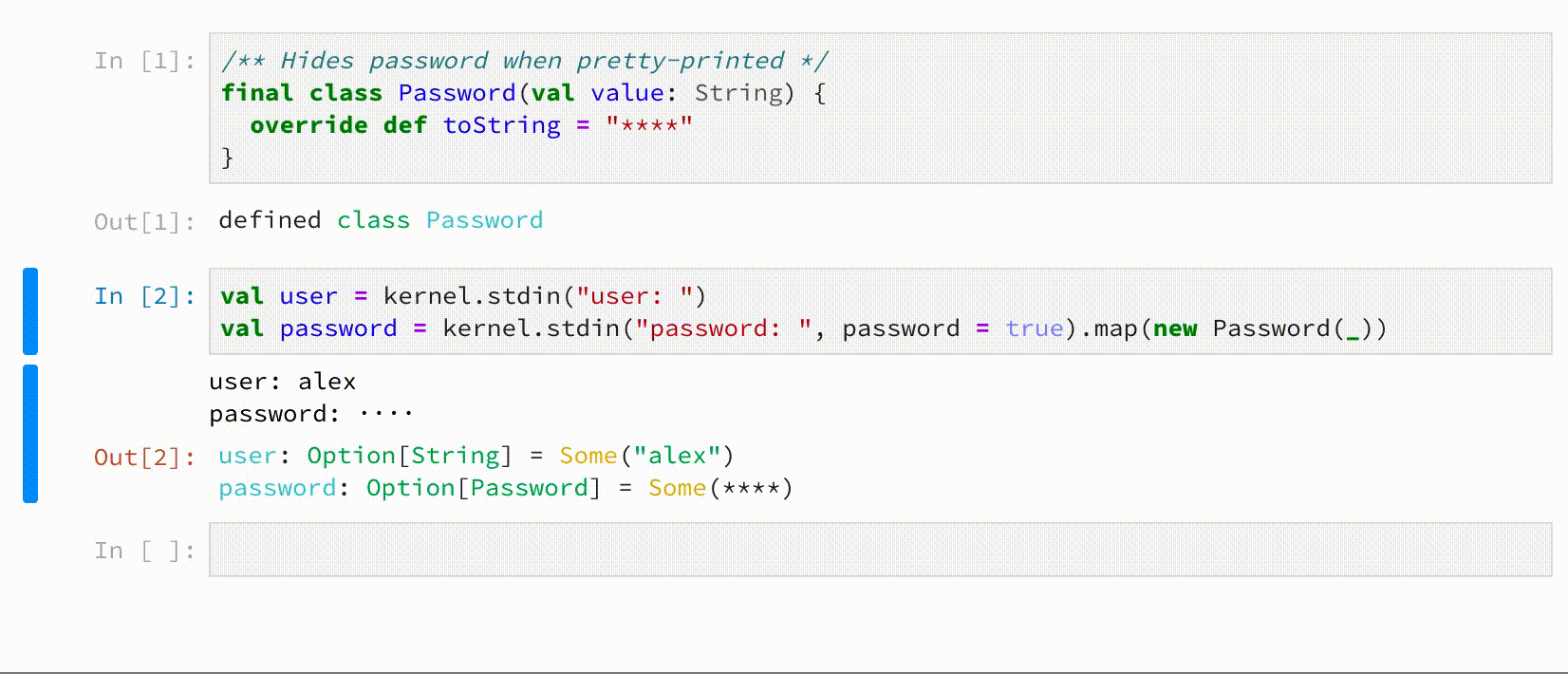
Comm messages
Comm messages are part of the Jupyter messaging protocol. They allow the exchange of arbitrary messages between code running in the front-end (typically JavaScript code) and kernels.
The comm API can be used to receive messages, or send them.
kernel.comm.receiver allows to register a target to receive messages from the front-end, like
val id = java.util.UUID.randomUUID().toString
kernel.publish.html("Waiting", id)
kernel.comm.receiver("A") { data =>
// received message `data` from front-end
kernel.publish.updateHtml(s"<code>$data</code>", id)
}
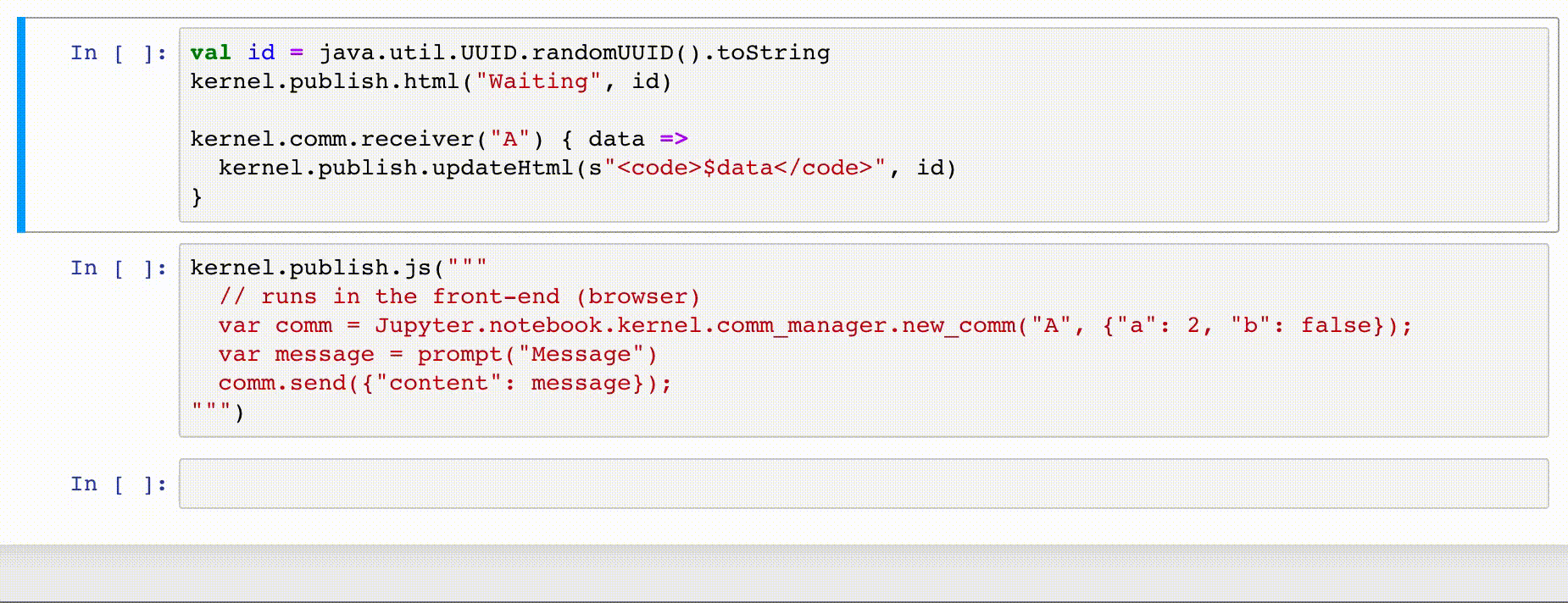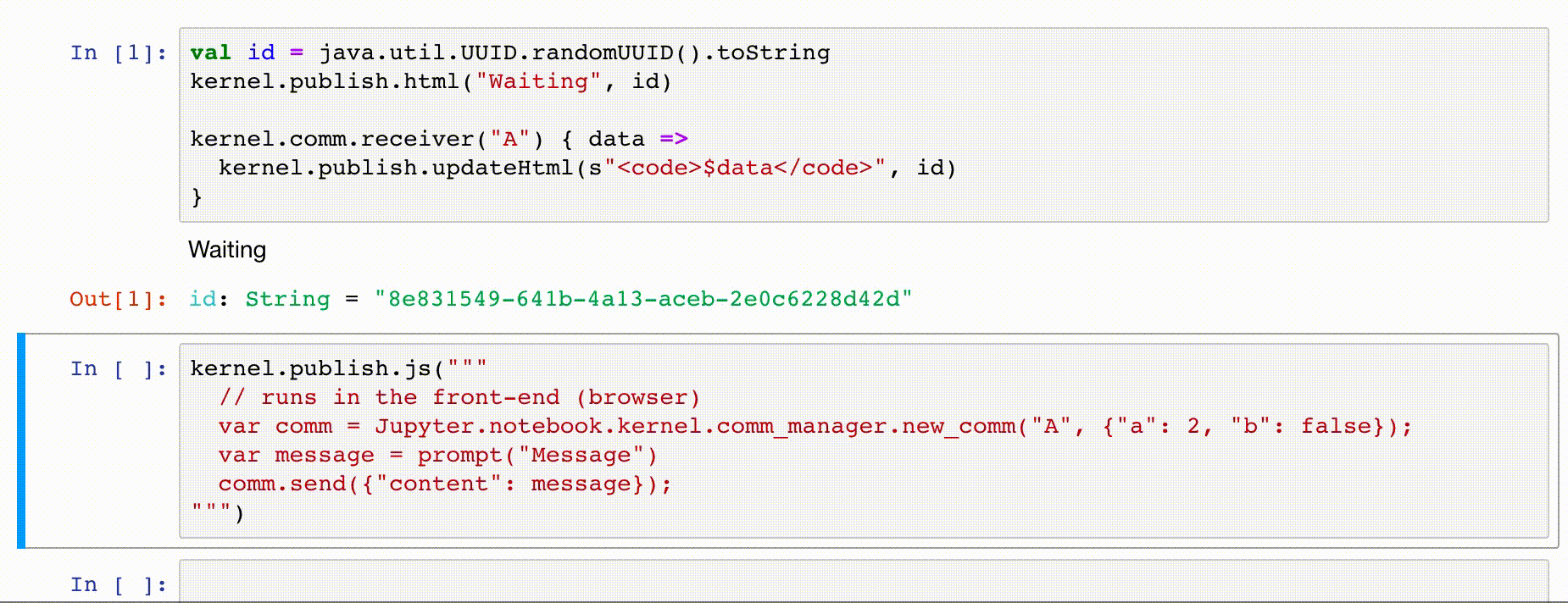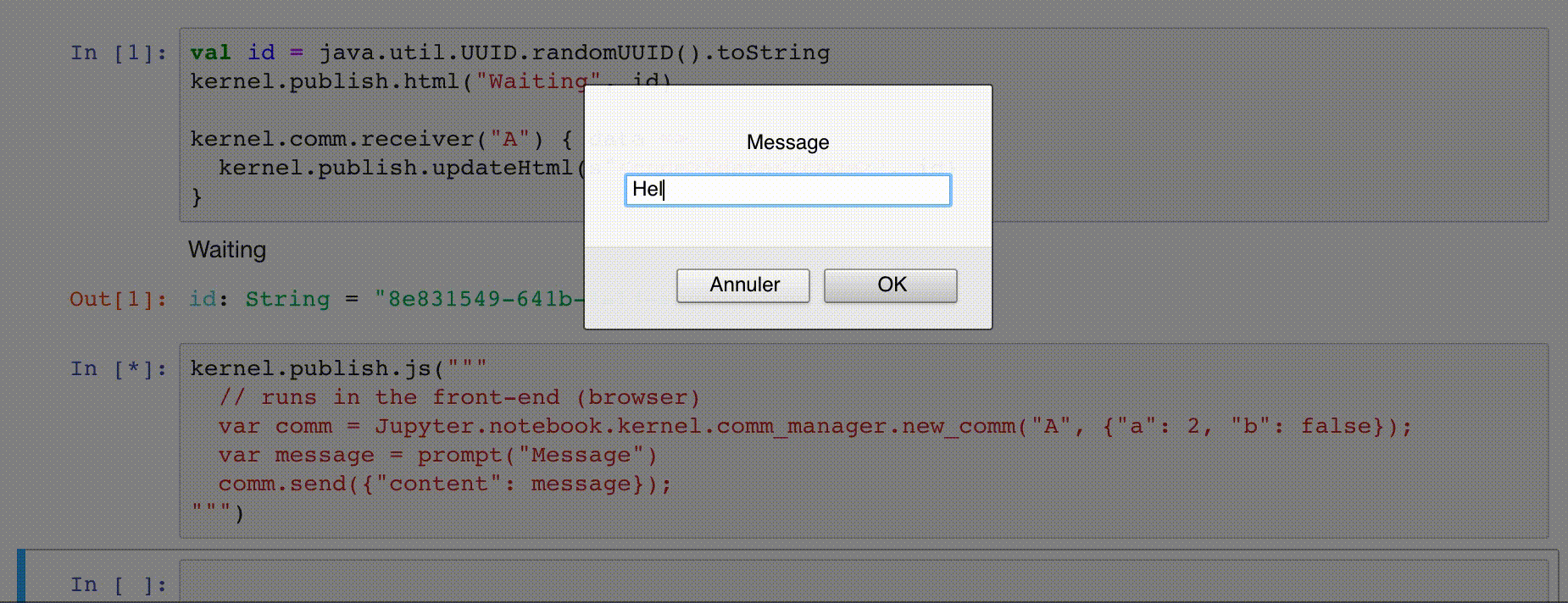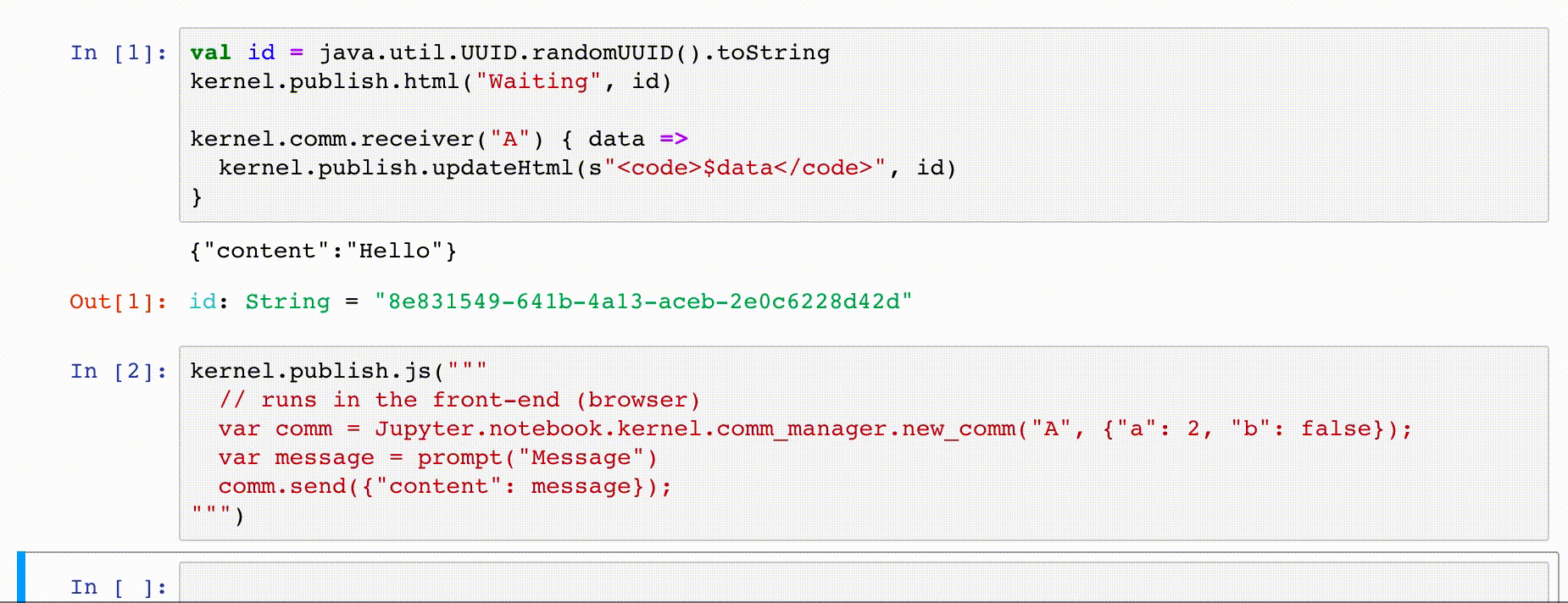
TODO Send to client
Display data
The publish field, of type almond.interpreter.api.OutputHandler, has numerous methods to push display data to the front-end.
The most generic is display, accepting a almond.api.DisplayData.
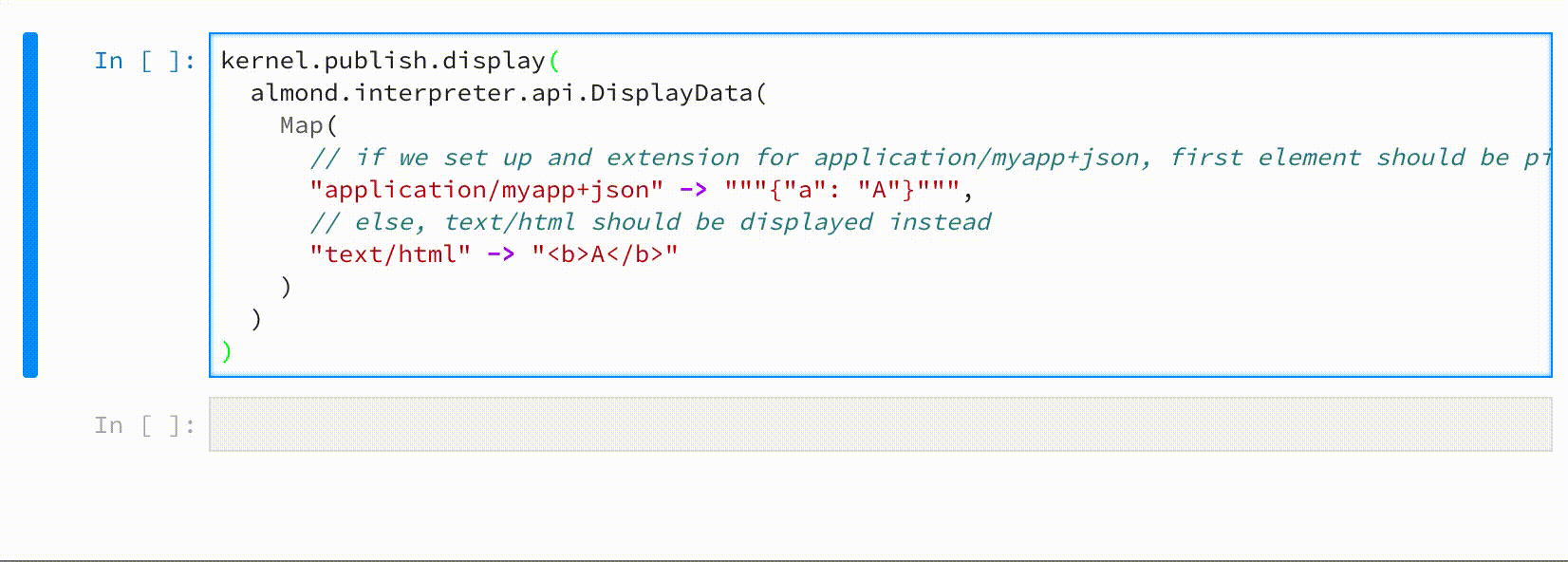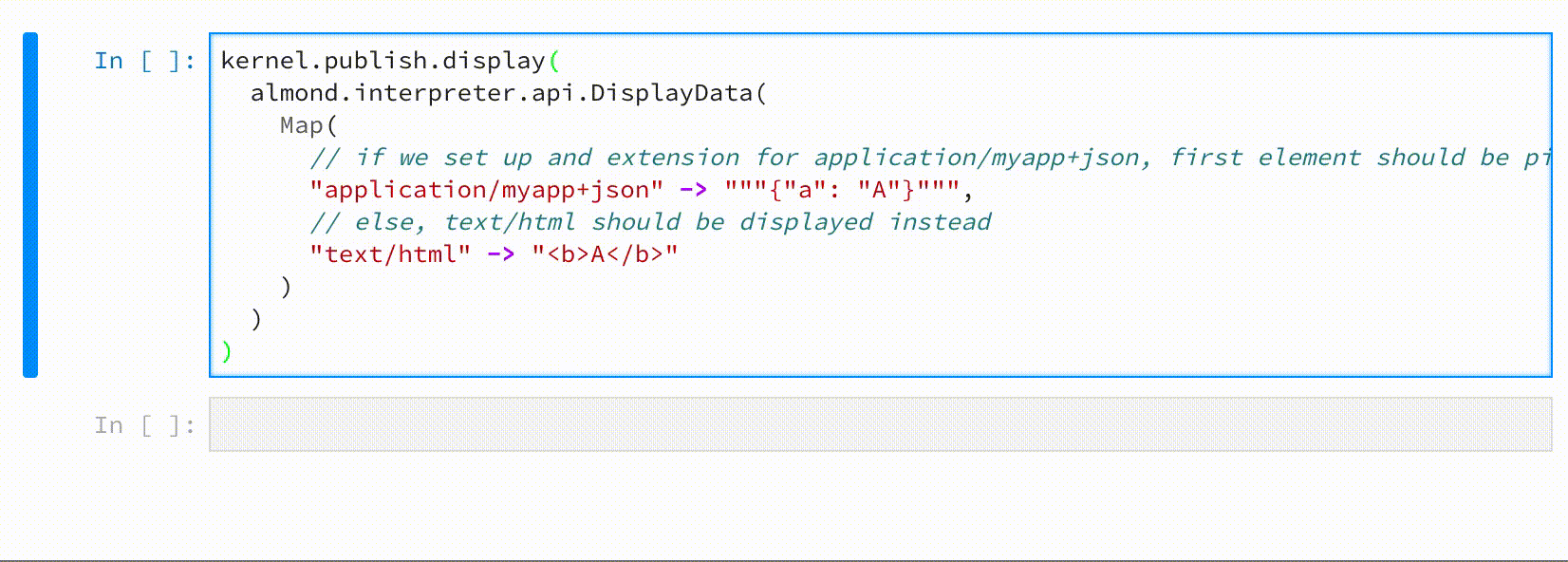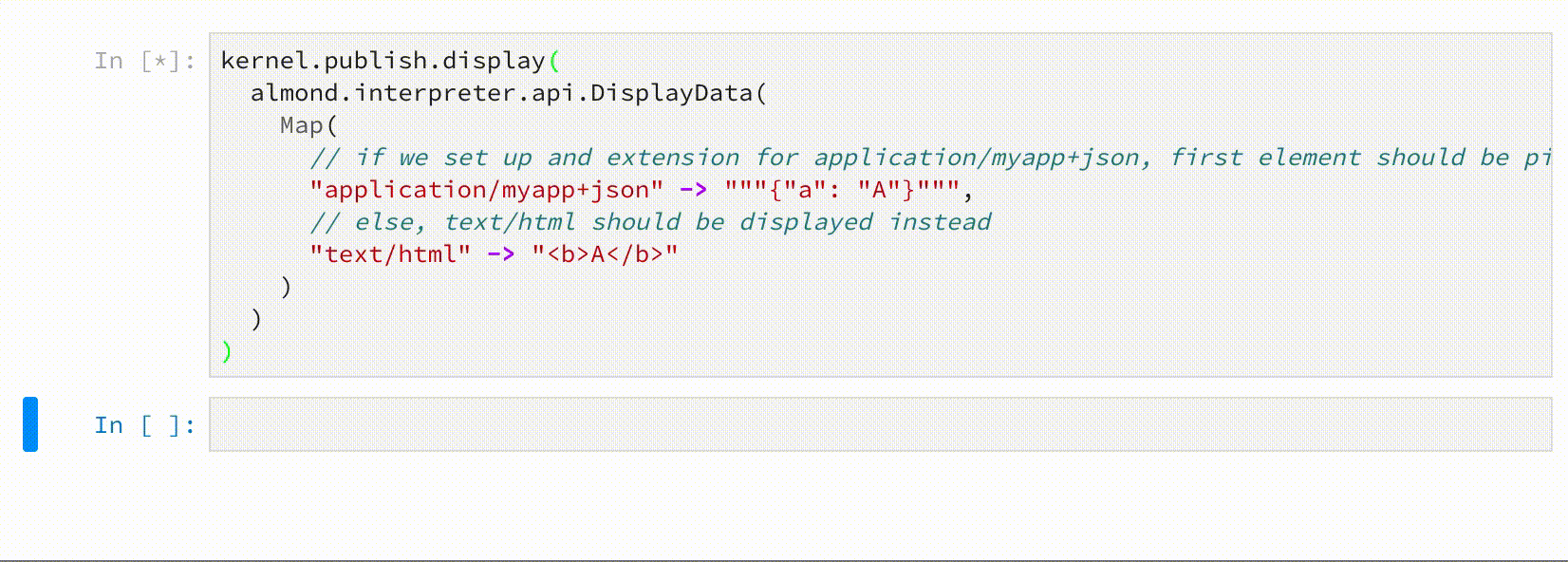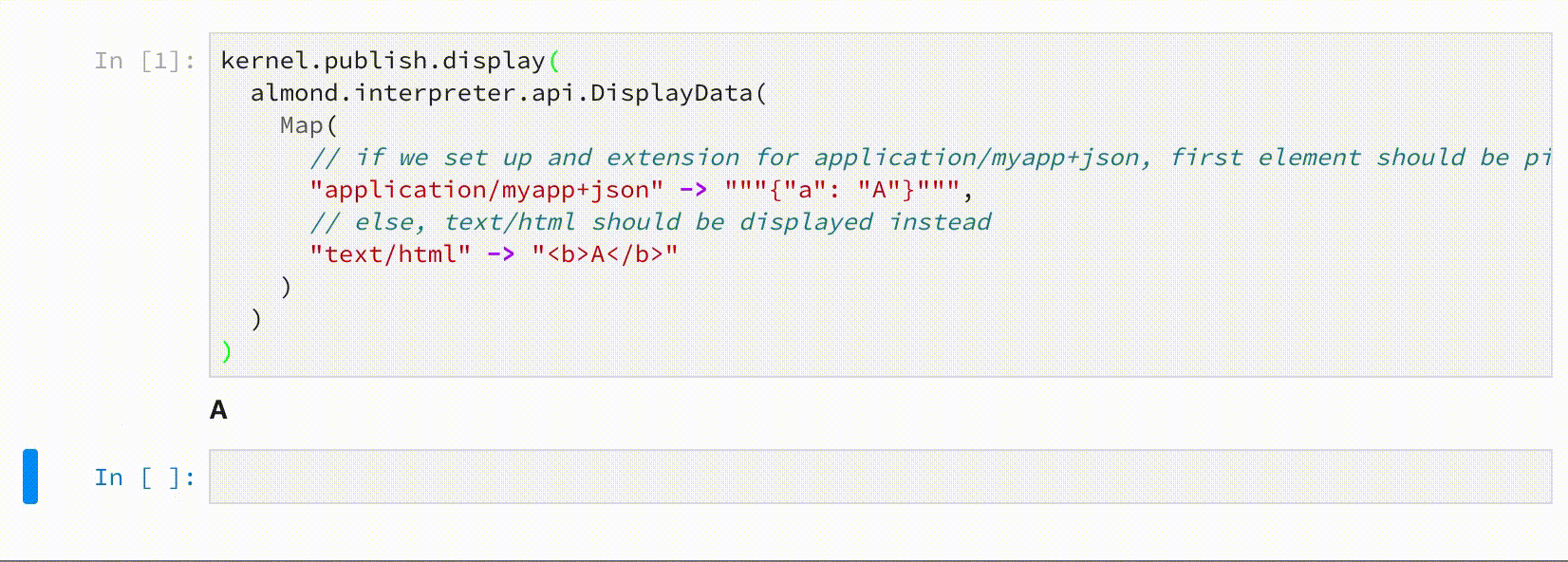
kernel.publish.display(
almond.interpreter.api.DisplayData(
Map(
// if we set up an extension for application/myapp+json, first element should be picked
"application/myapp+json" -> """{"a": "A"}""",
// else, text/html should be displayed
"text/html" -> "<b>A</b>"
)
)
)
OutputHandler also has helper methods to push HTML straightaway.
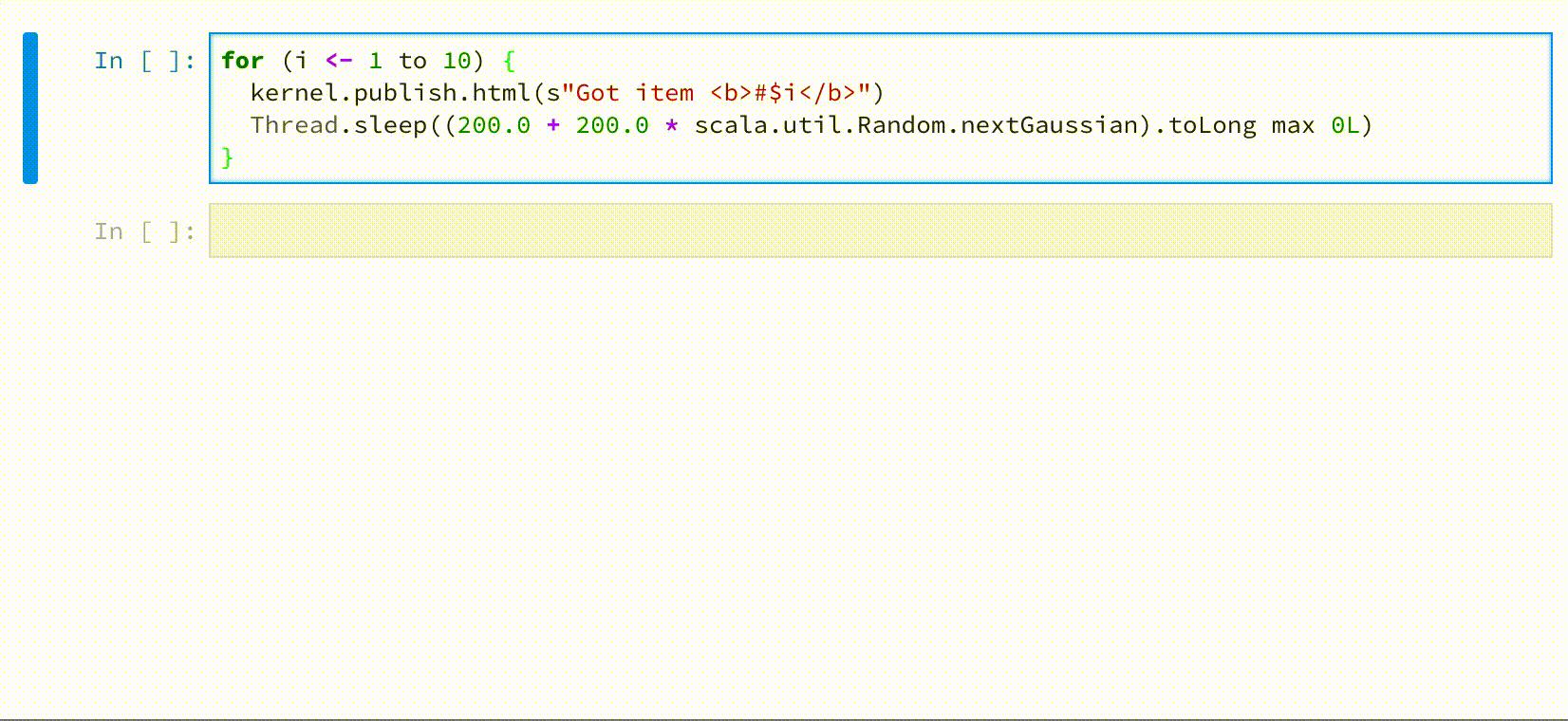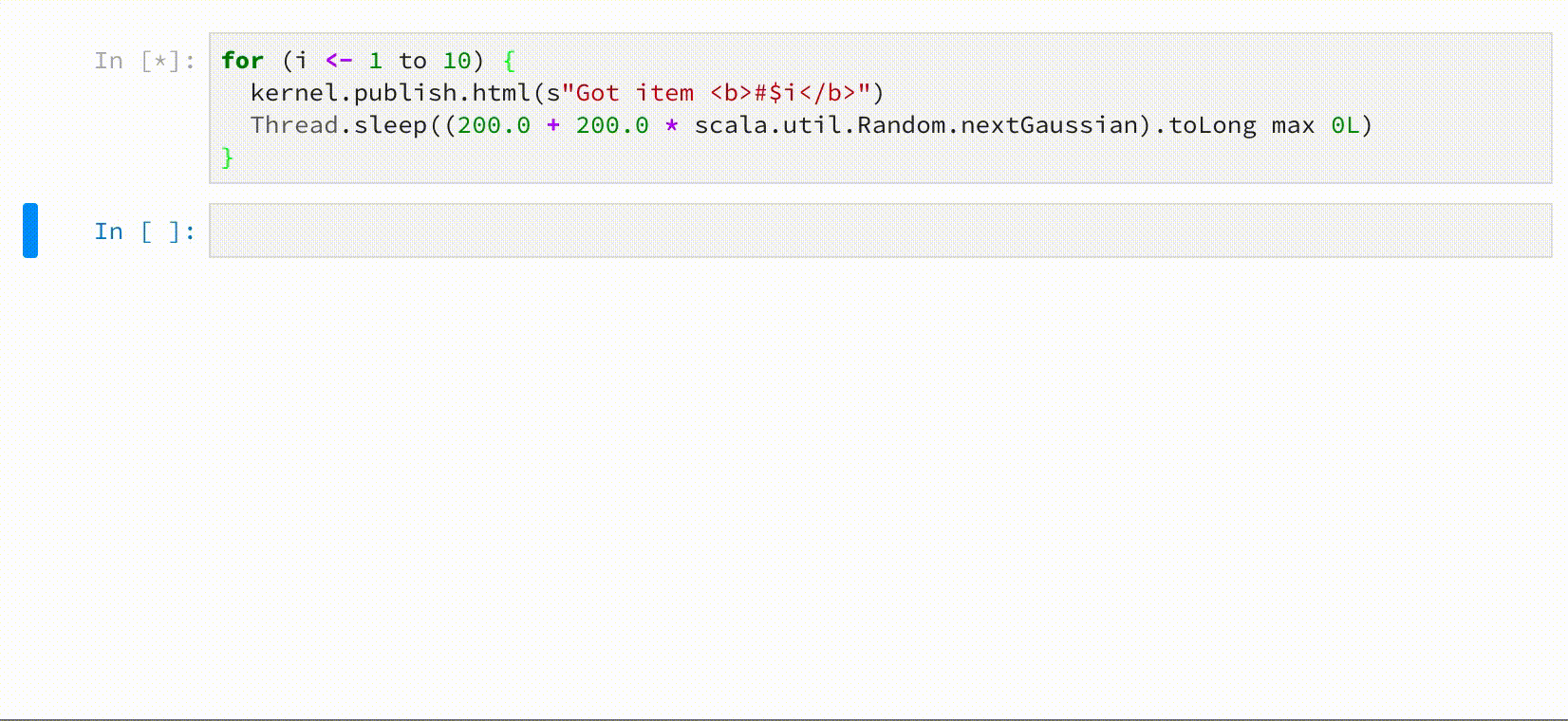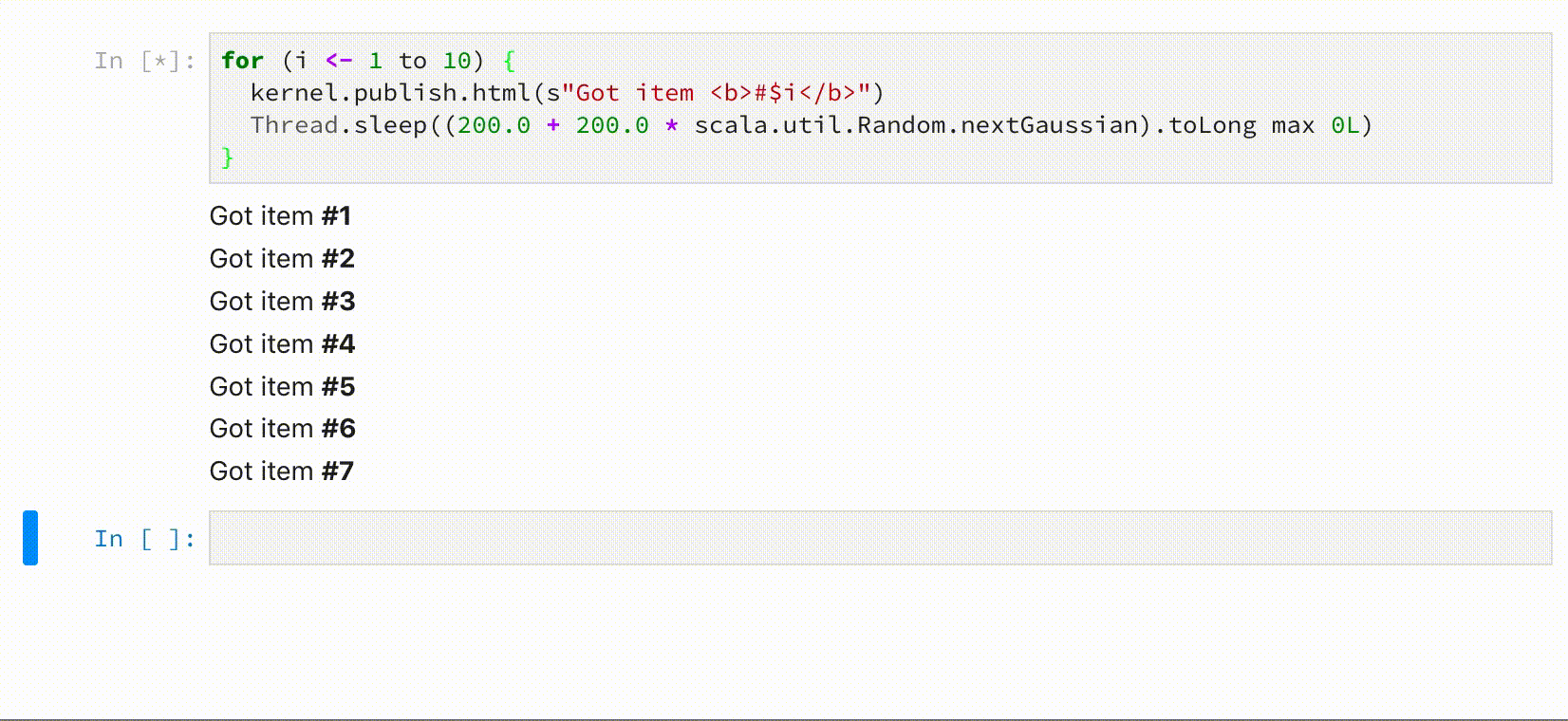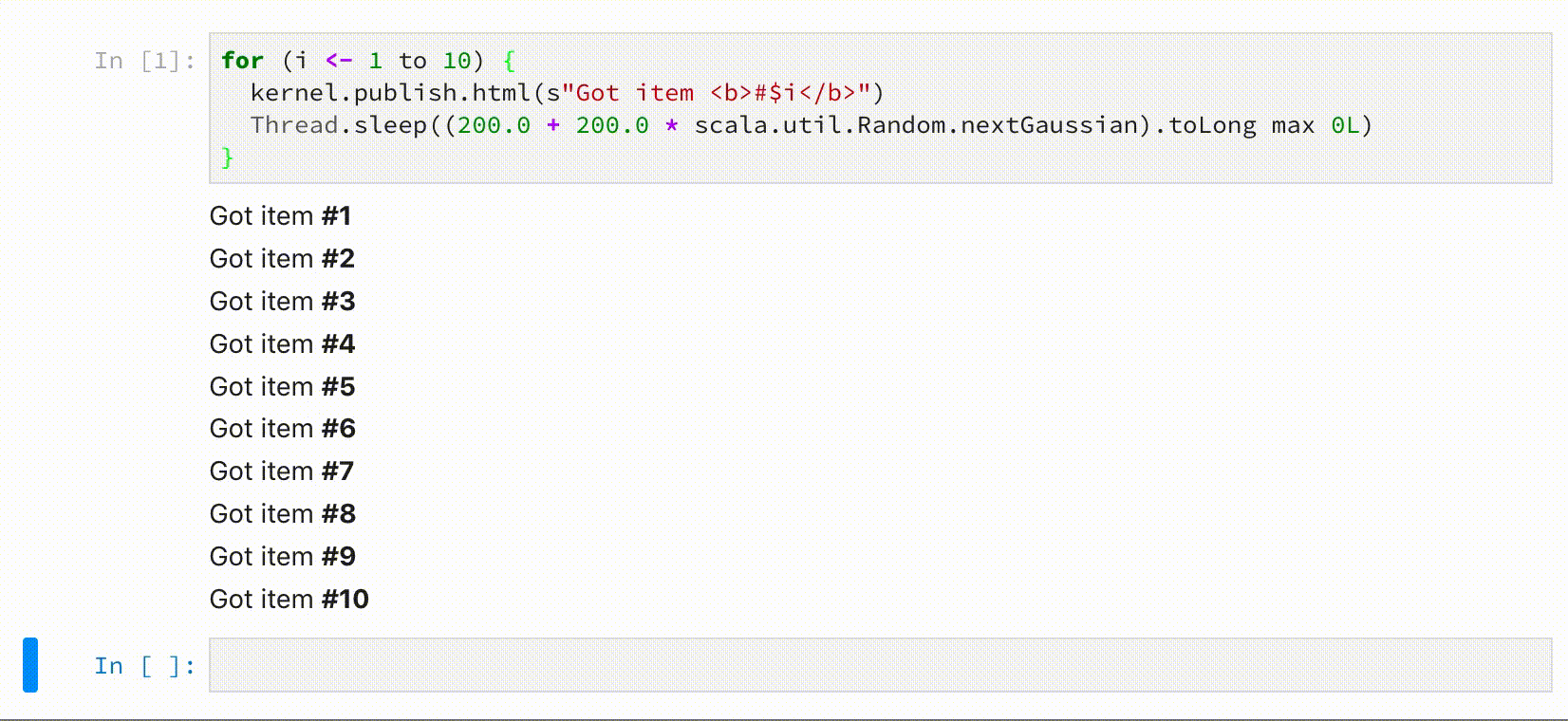
for (i <- 1 to 10) {
kernel.publish.html(s"Got item <b>#$i</b>")
Thread.sleep((200.0 + 200.0 * scala.util.Random.nextGaussian).toLong max 0L)
}
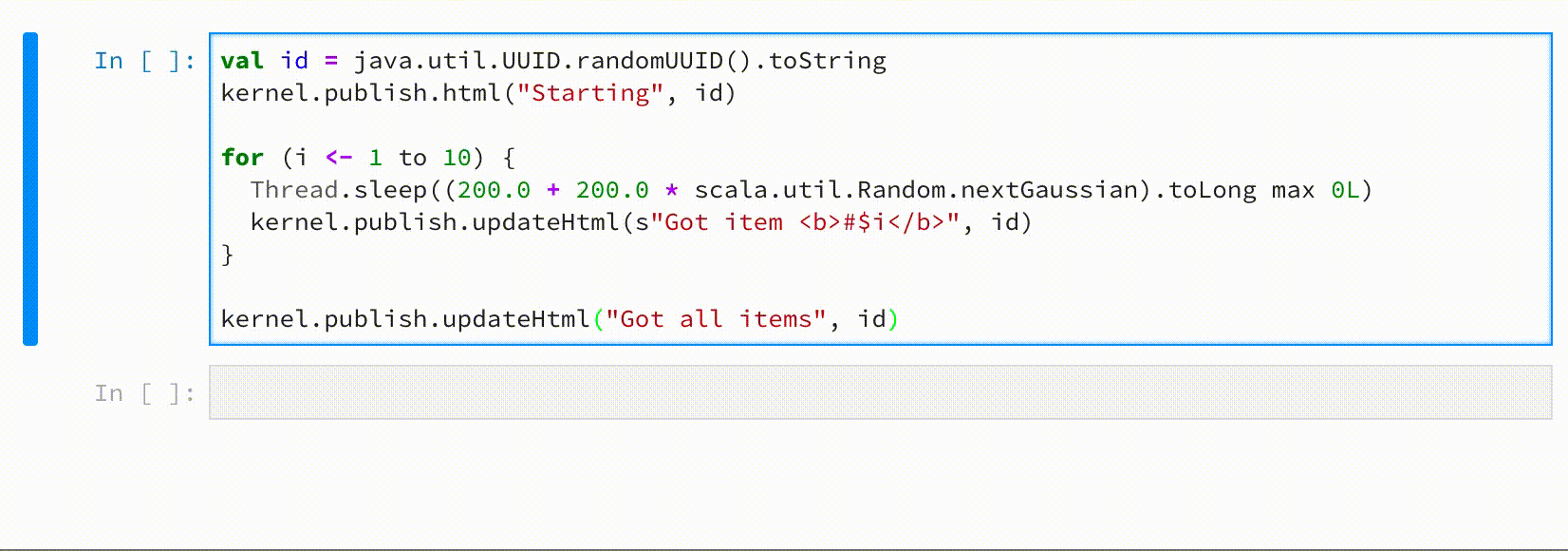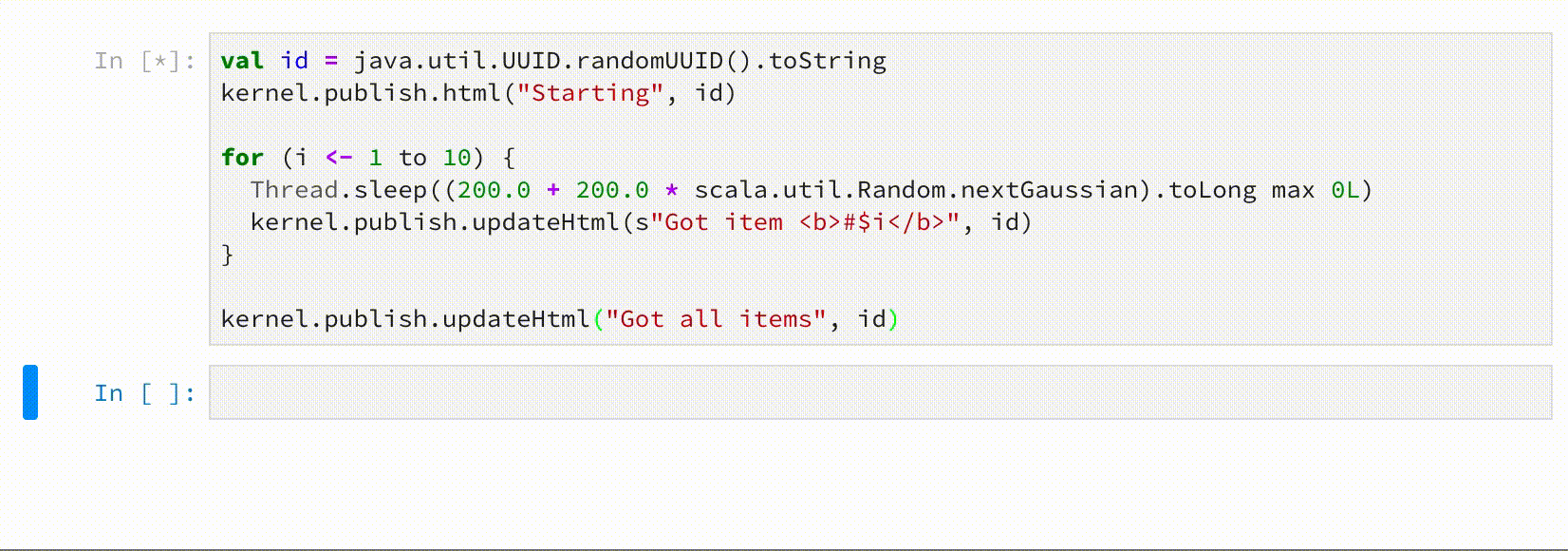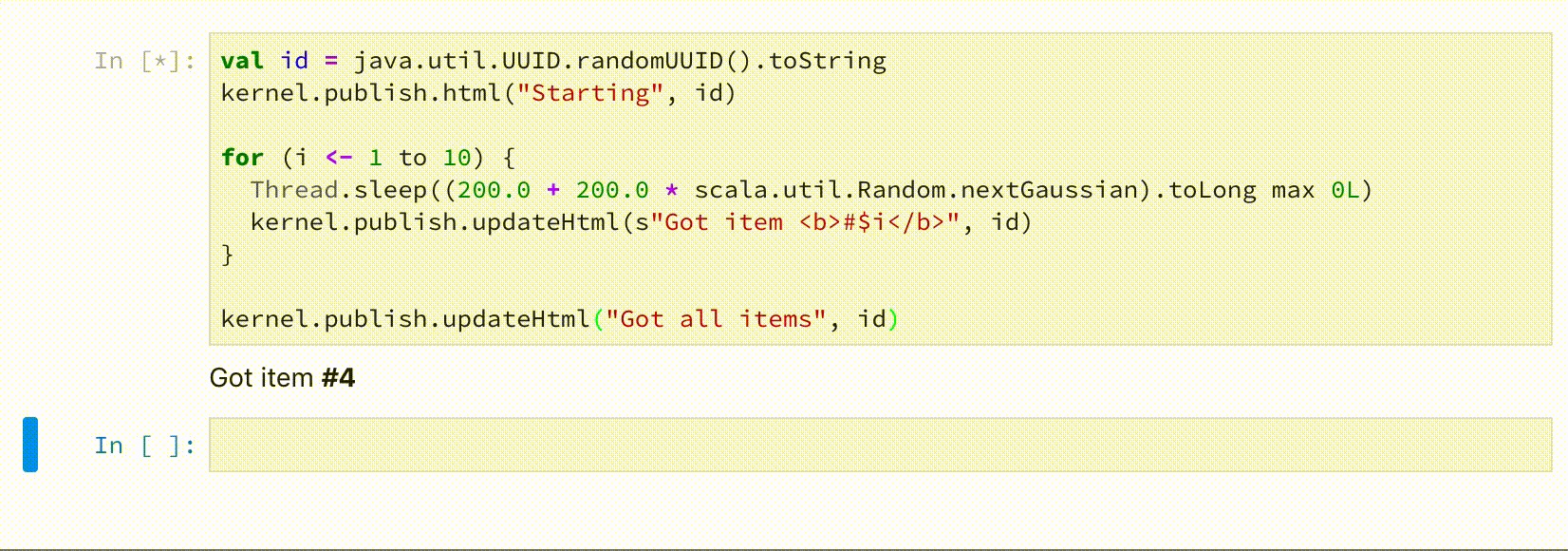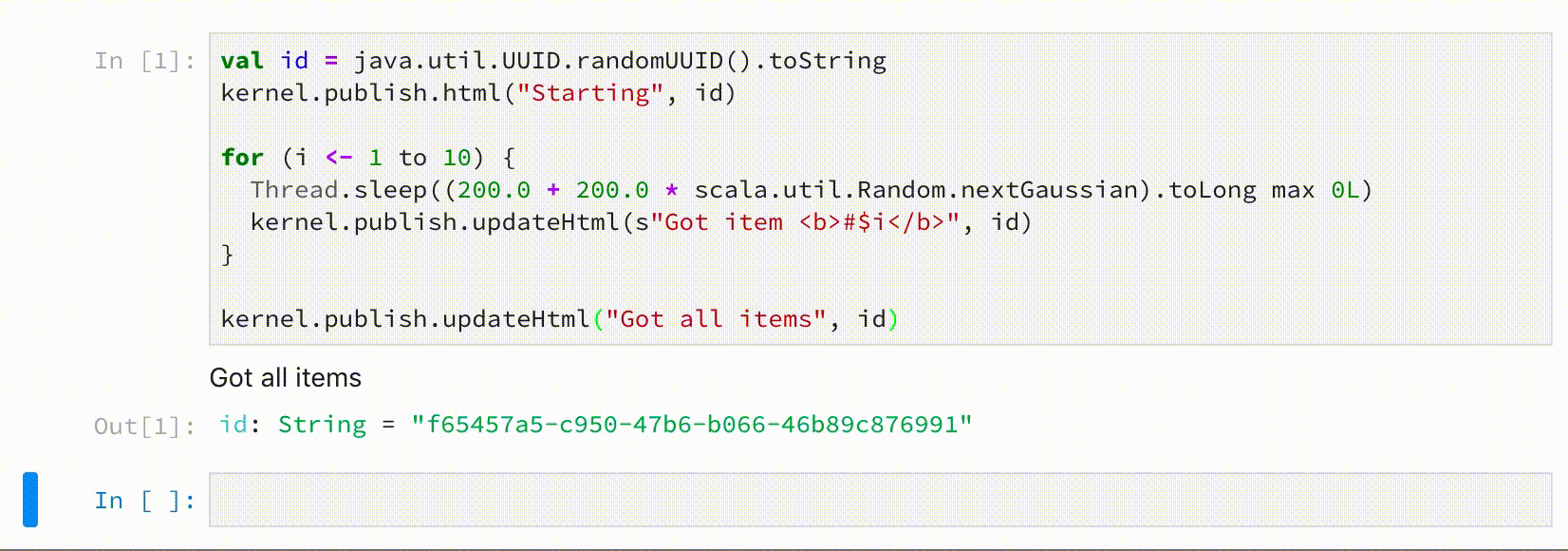
Updatable display data
If passed an id, when pushing some display data, OutputHandler allows to update that data later.
val id = java.util.UUID.randomUUID().toString
kernel.publish.html("Starting", id)
for (i <- 1 to 10) {
Thread.sleep((200.0 + 200.0 * scala.util.Random.nextGaussian).toLong max 0L)
kernel.publish.updateHtml(s"Got item <b>#$i</b>", id)
}
kernel.publish.updateHtml("Got all items", id)
After Interrupt Hooks
After Interrupt Hooks allow clean-up code to be run after cell execution is interrupted.
val sparkAmmonite = {
new AmmoniteSparkSessionBuilder()
.getOrCreate()
}
lazy val spark = {
NotebookSparkSession.builder()
.progress(enable=true, keep=false)
.logsInDeveloperConsole(false)
.getOrCreate()
}
lazy val sc = {
spark.sparkContext
}
// Add new hook with name "CancelAllSparkJobs"
kernel.addPostInterruptHook(
"CancelAllSparkJobs",
_ => sc.cancelAllJobs()
)
// Return a list with all registered hooks
kernel.postInterruptHooks
// Remove hook by name
kernel.removePostInterruptHook("CancelAllSparkJobs")
// Run after-interrupt hooks (called internally after a cell interrupt)
kernel.runPostInterruptHooks()
Since Scala anonymous functions don't print well after being compiled to bytecode each hook is registered with a name.
Hooks
Hooks allow to pre-process code right before it's executed. Use like
private def runSql(sql: String): String = {
println("Running query...")
val fakeResult =
"""<table>
|<tr>
|<th>Id</th>
|<th>Name</th>
|</tr>
|<tr>
|<td>1</td>
|<td>Tree</td>
|</tr>
|<tr>
|<td>2</td>
|<td>Apple</td>
|</tr>
|</table>
|""".stripMargin
fakeResult
}
kernel.addExecuteHook { code =>
import almond.api.JupyterApi
import almond.interpreter.api.DisplayData
if (code.linesIterator.take(1).toList == List("%sql")) {
val sql = code.linesWithSeparators.drop(1).mkString // drop first line with "%sql"
val result = runSql(sql)
Left(JupyterApi.ExecuteHookResult.Success(DisplayData.html(result)))
}
else
Right(code) // just pass on code
}
Such code can be run either in a cell or in a predef file.
Later on, users can run things like
%sql
SELECT id, name FROM my_table